https://programmers.co.kr/learn/courses/30/lessons/42576
코딩테스트 연습 - 완주하지 못한 선수
수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다. 마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수
programmers.co.kr
문제 요약 >
마라톤에 참여한 선수들과 완주하지 못한 선수의 이름이 주어질때, 완주하지 못한 선수의 이름을 리턴하라.
풀이 >
문제 풀이에는 다양한 방법이 존재한다. 그러나 문제 분류가 해시로 되어있어서 해시로 풀어보기로 했다. 이 문제는 무려 5만 8천명 이상이 완료한 문제이고 난이도 또한 Lv1이기 때문에 굉장히 쉽게 풀이가 될거라고 생각했지만 예상치 못한 부분에서 난관이 있었다. 바로 해시였다.
처음에 해시로 풀어야겠다고 생각하는 순간 당연히 해시 함수가 떠올랐고, 아래 첫번째 풀이와 같이 해시값을 계산해서 리턴해주는 hash_function을 먼저 짰다. 그리고 거기서부터 돌고도는 삽질이 시작됐다. (이래서 첫 접근이 중요하다)
결론부터 말하자면, 이 문제는 C++의 STL 중 hash 자료구조(unordered_map)를 사용해서 풀이가 가능한 문제이다. hash 자료구조 자체가 key - value 값으로 이루어진 것이고, STL을 사용해서 key에는 이름, value에는 등장 횟수를 담도록 마음먹은 이상 내가 따로 hash_function을 만들 필요는 없다.
부끄럽지만 나의 삽질을 기록.. 오늘도 하나 배웠다!
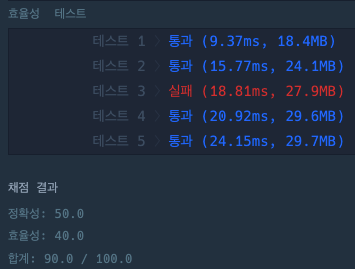
> 첫번째 풀이 : 참가자마다 이름도 담고싶고 등장횟수도 담고싶어! 이름을 hash_function에 넣어서 index를 얻은 후 테이블에 넣어두자.
결과 - 효율성 테스트 fail
#include <string>
#include <vector>
#include <iostream>
using namespace std;
#define MAX_TABLE 100000
struct PARTICIPANT {
string name;
int count;
};
PARTICIPANT partList[MAX_TABLE] = {{"", 0},};
int hash_function(string str) {
int hash = 401; int i = 0;
while (i < str.size()) {
hash = ((hash << 4) + (int)(str[i])) % MAX_TABLE;
i++;
}
return hash % MAX_TABLE;
}
string solution(vector<string> participant, vector<string> completion) {
int hashKey, i;
string answer = "";
for (i = 0; i < completion.size(); ++i)
{
hashKey = hash_function(completion[i]);
if (partList[hashKey].name.compare("") != 0)
{
partList[hashKey].count++;
}
else
{
partList[hashKey].name = completion[i];
partList[hashKey].count = 1;
}
}
for (i = 0; i < participant.size(); ++i)
{
hashKey = hash_function(participant[i]);
partList[hashKey].count--;
if (partList[hashKey].count < 0)
{
answer = participant[i];
return answer;
}
}
}
> 두번째 풀이 : map을 사용해야겠네! (지금 보니 시간복잡도는 첫번째 풀이랑 같은데 구조체만 바꿨다)
결과 - 효율성 테스트 fail
#include <string>
#include <vector>
#include <iostream>
#include <map>
using namespace std;
#define MAX_TABLE 100000
struct PARTICIPANT {
string name;
int count;
};
map<int, PARTICIPANT> mapset;
int hash_function(string str) {
int hash = 401; int i = 0;
while (i < str.size()) {
hash = ((hash << 4) + (int)(str[i])) % MAX_TABLE;
i++;
}
return hash % MAX_TABLE;
}
string solution(vector<string> participant, vector<string> completion) {
int hashKey, i;
string answer = "";
PARTICIPANT partList;
for (i = 0; i < completion.size(); ++i)
{
hashKey = hash_function(completion[i]);
partList.name = completion[i];
partList.count = 1;
if (mapset.find(hashKey) != mapset.end())
{
mapset[hashKey].count++;
}
else
{
mapset.insert(pair<int, PARTICIPANT>(hashKey, partList));
}
}
for (i = 0; i < participant.size(); ++i)
{
hashKey = hash_function(participant[i]);
if (mapset.find(hashKey) == mapset.end())
{
answer = participant[i];
return answer;
}
mapset[hashKey].count--;
if (mapset[hashKey].count < 0)
{
answer = participant[i];
return answer;
}
}
}
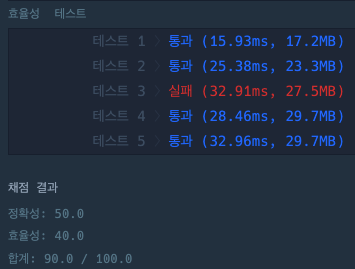
> 세번째 풀이 : 아니 세상에 unordered map이라는게 있다네?! 레드블랙트리를 사용해서 자동으로 정렬을 해두는 map에 비해, 해시 기반이자 정렬을 하지 않는 unordered map을 사용하면 조금 더 빠르지 않을까? (시험 결과 조금 더 빠르긴 했다)
결과 - 효율성 테스트 fail
#include <string>
#include <vector>
#include <iostream>
#include <unordered_map>
using namespace std;
#define MAX_TABLE 100000
struct PARTICIPANT {
string name;
int count;
};
unordered_map<int, PARTICIPANT> mapset;
int hash_function(string str) {
int hash = 401; int i = 0;
while (i < str.size()) {
hash = ((hash << 4) + (int)(str[i])) % MAX_TABLE;
i++;
}
return hash % MAX_TABLE;
}
string solution(vector<string> participant, vector<string> completion) {
int hashKey, i;
string answer = "";
PARTICIPANT partList;
for (i = 0; i < completion.size(); ++i)
{
hashKey = hash_function(completion[i]);
partList.name = completion[i];
partList.count = 1;
if (mapset.find(hashKey) != mapset.end())
{
mapset[hashKey].count++;
}
else
{
mapset.insert(pair<int, PARTICIPANT>(hashKey, partList));
}
}
for (i = 0; i < participant.size(); ++i)
{
hashKey = hash_function(participant[i]);
if (mapset.find(hashKey) == mapset.end())
{
answer = participant[i];
return answer;
}
mapset[hashKey].count--;
if (mapset[hashKey].count < 0)
{
answer = participant[i];
return answer;
}
}
}
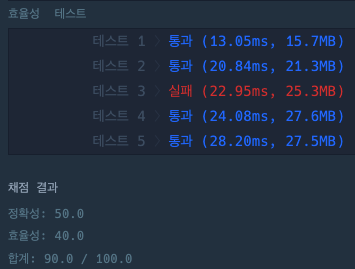
> 네번째 풀이 : 왜 꼭 구조체에 String을 넘겨줘야 했던 것일까! 이미 String을 사용해서 hash key를 얻었는데 말이다. (엄밀히 따지면 중복인 경우를 고려해야할수도 있지만 이 문제는 단순 최적화 문제인 것 같아서 고려하지 않았다) unordered_map<int, int>를 사용해서 hash값과 등장 횟수만 저장했다.
결과 - 효율성 테스트 fail
#include <string>
#include <vector>
#include <iostream>
#include <unordered_map>
using namespace std;
#define MAX_TABLE 100000
unordered_map<int, int> mapset;
int hash_function(string str) {
int hash = 401; int i = 0;
while (i < str.size()) {
hash = ((hash << 4) + (int)(str[i++])) % MAX_TABLE;
}
return hash % MAX_TABLE;
}
string solution(vector<string> participant, vector<string> completion) {
int hashKey, i;
string answer = "";
for (i = 0; i < completion.size(); ++i)
{
hashKey = hash_function(completion[i]);
if (mapset.find(hashKey) != mapset.end()) mapset[hashKey]++;
else mapset.insert(pair<int, int>(hashKey, 1));
}
for (i = 0; i < participant.size(); ++i)
{
hashKey = hash_function(participant[i]);
if (mapset.find(hashKey) == mapset.end())
{
answer = participant[i];
return answer;
}
mapset[hashKey]--;
if (mapset[hashKey] < 0)
{
answer = participant[i];
return answer;
}
}
}
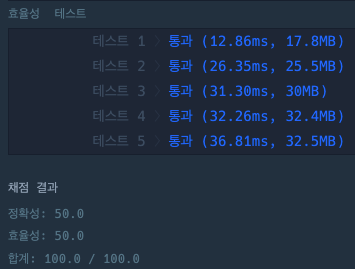
> 마지막 풀이 : STL을 쓰면서 해시 키를 만들어서 쓰는게 잘못됐다는 걸 알았다. unordered_map<string, int>를 사용해서 참가자의 이름과 등장 횟수를 넣었다. 기존에는 string 값으로 index를 직접 찾았던 반면, 해당 풀이로는 index를 구현자가 알 필요는 없다는 것이 특징이다.
한가지 주의해야할 점은, mapset[completion[i]]++와 같은 방법이다. [ ]를 사용하면 기본적으로 '접근'하는 동작만을 떠올리지만, map이나 unordered map에서는 '생성' -> '접근'이다. key가 없으면 key를 생성하는 것이다. 이를 잘 알지 못하고 사용하는 경우 의도되지 않은 동작을 유발할 수 있다. (작년에 업무 중에 map으로 뭔가를 구현할 일이 있어서 구현했는데, 조회하는 커맨드를 수행할때마다 없는 key가 생겼던걸 생각하면 웃프다..)
다른 분들의 코드를 참조하니 보통은 participant에 대한 처리를 하고, completion에 대한 처리를 한 후, 남아있는 것을 찾아서 리턴해주던데 나는 위의 과정(삽질)을 거치며 뭐라도 최적화를 더 하려고 하다보니.. completion에 대한 처리를 먼저 하고 participant에 대한 처리를 하면 마지막에 루프를 한번 더 돌지 않아도 된다는 생각이 들어서 요렇게 짰다.
결과 - 드디어 성공
#include <string>
#include <vector>
#include <iostream>
#include <unordered_map>
using namespace std;
unordered_map<string, int> mapset;
string solution(vector<string> participant, vector<string> completion) {
int hashKey, i;
string answer = "";
for (i = 0; i < completion.size(); ++i)
{
mapset[completion[i]]++;
}
for (i = 0; i < participant.size(); ++i)
{
mapset[participant[i]]--;
if (mapset[participant[i]] < 0)
{
answer = participant[i];
return answer;
}
}
}
> 진짜진짜 마지막 풀이_final_최종 : 존재 유무를 확인하지 않고 mapset[]으로 접근하는 것은 좋지 못한 방법인 것 같아서 예쁘게 짜보았다.
#include <string>
#include <vector>
#include <iostream>
#include <unordered_map>
using namespace std;
unordered_map<string, int> mapset;
string solution(vector<string> participant, vector<string> completion) {
int hashKey, i;
string answer = "";
for (i = 0; i < completion.size(); ++i)
{
if (mapset.find(completion[i]) != mapset.end()) mapset[completion[i]]++;
else mapset.insert(make_pair(completion[i], 1));
}
for (i = 0; i < participant.size(); ++i)
{
if (mapset.find(participant[i]) != mapset.end())
{
mapset[participant[i]]--;
if (mapset[participant[i]] < 0) return participant[i];
}
else return participant[i];
}
}'PROBLEM SOLVING > 프로그래머스' 카테고리의 다른 글
| 프로그래머스 / 더 맵게 (0) | 2022.01.31 |
|---|---|
| 프로그래머스 / 문자열 압축 (0) | 2022.01.18 |
| 프로그래머스 / 숫자 문자열과 영단어 (0) | 2022.01.17 |
| 프로그래머스 / 신규 아이디 추천 (0) | 2022.01.17 |
| 프로그래머스 / 로또의 최고 순위와 최저 순위 C++ 풀이 (0) | 2022.01.16 |